This article describes various Isolation levels supported by a Transactional Database, the various problems addressed by each Isolation level, and how the database implements core abstractions for each Isolation level.
Before we get into the details of Database Isolation, let’s first understand the meaning of a Transaction and the role of various properties associated with it.
Introduction
In a database management system, a Transaction is a way of grouping multiple operations together as a single unit of work such that either all the operations are executed successfully or none of them are executed.
On failure, the client can safely retry since the database guarantees no partial updates.
Following are the four important properties of a database Transaction which are commonly referred to by the acronym ACID.
- Atomicity: Atomicity is a property of Transaction which represents an indivisible unit of work. A Transaction involving multiple operations is either executed successfully (commit) or aborted completely (rollback) discarding any partial writes.
- Consistency: Consistency is a client-specific property of Transaction which represents the database transitioning from one valid state to another preserving database constraints such as unique constraints, referential integrity. This is considered a weaker guarantee since the valid transitioning is defined by the client, not the database and the database makes no guarantee in preventing invalid transition.
- Isolation: Isolation is a property of a Transaction that defines the visibility semantics of concurrently running transactions. It describes how and when parts of the transaction should be visible to other concurrently running transactions.
- Durability: Durability is a property of Transaction that guarantees that once a Transaction is successfully committed, it is stored reliably surviving crashes. The term Durability might mean different for different databases such as persistence to disk, replication, archival to cold storage, etc…
Isolation Levels
The following sections explain each Isolation Level in detail, its implication, and its implementation.
It is important to understand the implications of each Isolation Level. It helps in troubleshooting concurrency bugs and also trying to understand the use cases each Isolation caters to / doesn’t cater to along with its performance characterestics.
Read Uncommitted Isolation Level
Read Uncommitted is one of the weakest Isolation Levels provided by Transactional Databases.
As the name implies, it allows Transactions to read uncommitted values in the presence of concurrent write Transactions. If the Transaction is later rolled back, the clients would have read value that never existed.
Read Uncommitted Isolation Level doesn’t address any of the problems associated with Dirty Reads, Dirty Writes, Lost Update Problem, Non-Repeatable Reads, and Phantom Reads. (All these concepts are described in the subsequent sections below)
Since this behavior is undesirable by most of the clients, most databases do not support this Isolation Level.
Read Committed Isolation Level
Read Committed is one of the basic Isolation levels provided by Transactional Databases.
PostgreSQL is bundled with Read Committed as the default Isolation level.
Before we deep dive into this, we need to understand two very important concepts: Dirty Reads and Dirty Writes.
- Dirty Reads: If a Transaction includes a series of write operations and executes certain write operations and if another Transaction reads the values written by the first Transaction before it is committed, then the scenario is considered as Dirty Read.
- Dirty Writes: If there are two Transactions concurrently writing to the database to the same set of rows and if the first Transaction executes write operations followed by the second Transaction overwriting the values written by the first Transaction before it is committed, then the scenario is considered as Dirty Write.
Problems Addressed
Databases that guarantee Read Committed Isolation Level prevents Dirty Reads and Dirty Writes.
If the database returns uncommitted values (Dirty Reads), and if the Transaction is later aborted, the database would have returned values to the client which was subsequently rolled back later leading to data inconsistency.
If the database allows overwriting uncommitted values (Dirty Writes), and if the first Transaction is later aborted, the latter transaction would end up using the value which was subsequently rolled back later leading to data inconsistency.
Databases prevent Dirty Reads by ensuring that every read returns only the values that were committed to the database and not the value that is being written by an ongoing transaction.
Databases prevent Dirty Writes by ensuring that every write only overwrites the values that were committed to the database and not the value that is being written by an ongoing transaction.
Implementation
Database prevents Dirty Reads by keeping a maximum of two copies of data: the committed value and the uncommitted value being written by the ongoing write Transaction.
Any reads to the rows which have an ongoing write Transaction always return the committed (old) value. The uncommitted value remains local to the ongoing write Transaction until it is committed in which case, the database makes uncommitted value live atomically.
Database prevents Dirty Writes by taking row-level locks on the rows on which it has to modify. Concurrent write operations on the same objects will have to wait until the first Transaction eventually commits/aborts and release the lock.
Problems Not Addressed
Read Committed Isolation Level doesn’t address the problems associated with Non-Repeatable Reads and Phantom Reads which are explained in subsequent sections.
Repeatable Reads Isolation Level
We need to understand Non-Repeatable Reads before we deep dive into the Repeatable Reads Isolation Level.
A Non-Repeatable Read occurs when executing a Transaction, we read the same rows(s) multiple times and get different results for those rows. This behavior is also referred to as Read Skew.
To understand why this is important, let’s take an example of a Transaction that involves multiple reads and writes.
// Transaction 1
BEGIN TRANSACTION// Returns dob
Operation 1: SELECT dob FROM users WHERE user_id = 1;// Returns a different dob
Operation 2: SELECT dob FROM users WHERE user_id = 1;END TRANSACTION// Transaction 2
UPDATE users SET dob = now() WHERE user_id = 1;
Let’s say two Transactions Transaction 1 and Transaction 2 are running concurrently. Following are the sequence of interleaving operations in Transaction 1 and Transaction 2
Transaction 1: Operation 1
Transaction 2
Transaction 1: Operation 2In this scenario, Operation 1 and Operation 2 return different results since an update operation from a different Transaction interleaved even though both are firing the same query.
This is problematic in real-world scenarios such as a database taking a snapshot and seeing different results at different points in time.
Problems Addressed
Databases supporting Repeatable Reads Isolation Level prevents Non-Repeatable Reads, Dirty Reads and Dirty Writes. Simply put, it addresses all the use cases of Read Committed Isolation Level along with preventing Non-Repeatable Reads,
MySQL is bundled with Repeatable Reads as the default Isolation level.
Non Repeatable Reads are prevented by databases by implementing Snapshot Isolation.
The basic idea behind Snapshot Isolation is that every Transaction reads all the committed rows required for executing reads and writes before the start of the Transaction and every operation in the Transaction reads from this consistent snapshot.
Any changes made to the relevant rows after the Transaction starts by a different Transaction is not considered by the ongoing Transaction and the decision of conflict resolution on the rows concurrently modified is made at the time of commit.
Implementation
Snapshot Isolation is implemented by maintaining multiple versions of the same row at a given point in time, due to multiple concurrent transactions.
Each row in the table has two hidden fields namely created_by and deleted_by which indicates the Transaction that created this row and deleted this row respectively.
Each Transaction is identified by a monotonically increasing Transaction Identifier which is used to tag created_by and deleted_by fields.
Let’s understand this concept using an example.
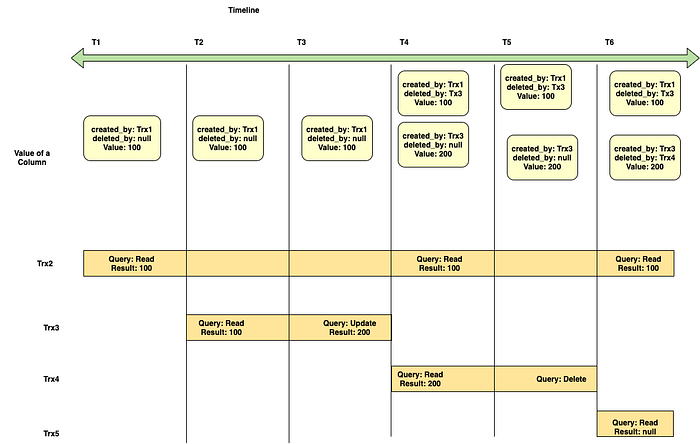
Consider a time interval from T1 from T6 where different transactions (Trx2, Trx3, Trx4, Trx5) are interleaved and the initial value of the column is 100
- Timeline T1: Trx2 is started and executes a Read Query to get the result as 100.
- Timeline T2: Trx2 is still active but doesn’t run any query in this timeline. Concurrently, another Trx3 is started and executes a Read Query to get the result as 100.
- Timeline T3: Trx2 is still active but doesn’t run any query in this timeline. Concurrently, Trx3 executes an Update query to change the result to 200, and subsequently, Trx3 is closed. Now at the end of this timeline T3, we have two versions of the value: The value 100 created by Trx1 and deleted by Trx3 and the value 200 created by Trx3 as shown in the diagram.
- Timeline T4: Trx2 is still active and when executed a Read Query, the result 100 is returned since that was the committed value at the start of Trx2. Concurrently, Trx4 is started and when executed the Read Query is, the value returned is 200 since this is the latest value committed.
- Timeline T5: Trx2 is still active but doesn’t run any query in this timeline.Trx4 is still active and executes the Delete query on the value. Now at the end of timeline T5, we have two versions of the value: The value 100 created by Trx1 and deleted by Trx3 and the value 200 created by Trx3 and deleted by Trx4
- Timeline T6: Trx2 is still active and when executed a Read Query, the result 100 is returned since that was the committed value at the start of Trx2. Concurrently, Trx5 is started and when executed a Read Query, it returns an empty value since the value was removed before the start of Trx5
Since the database maintains multiple versions of the rows at a given point in time, periodically the database management system runs a Garbage Collection process and removes deleted and unreferenced entries from the table freeing up space.
This technique of maintaining multiple versions of rows on reads and writes while providing consistent and concurrent access to various ongoing transactions is commonly referred to as MVCC (Multi-version Concurrency Control).
Since the database implementing Non-Repeatable Reads also addresses Read Committed Isolation use cases, writes to the same row from concurrent transactions are streamlined using row-level locks preventing transactions from overstepping each other values.
Snapshot Isolation maintains the consistency of a Read Transaction in the presence of concurrent writes.
Problems Not Addressed
Repeatable Reads Isolation Level doesn’t address the problems associated with Phantom Reads and Write Skew which is discussed in the following section.
There is a different class of conflict problems called Lost Update Problems which is not directly addressed by Repeatable Reads Isolation Level which is discussed in the last section.
Serializable Isolation Level
Before getting into the Serializable Isolation Level, we need to understand two very important concepts: Phantom Reads and Write Skew.
Phantom Reads is an extension of Non-Repeatable Reads.
In the case of Non-Repeatable Reads, a Transaction reading the same row/(s) multiple times, returns the same number of rows but might return different results.
Phantom Reads occur when a Transaction reading the same set of row/(s) multiple times, returns different numbers of rows which can happen when new rows are INSERTED or DELETED between subsequent execution.
Write Skew is a generalized extension of the Lost Update Problem (described in the last section).
Write Skew is a specific case of Lost Update Problem where-in two Transactions read the same rows but update some of those rows (different transactions may update different rows).
Let’s take an example to understand why this problem is important in the real world.
If we are building a Meeting Room booking application, two clients want to book a meeting room at the same time interval. Both the clients read the meeting room availability for a time frame and conclude the meeting room is free for the time interval and try to book the room creating conflicts.
Problems Addressed
Databases implementing Serializable Isolation Level prevent Phantom Reads and Write Skew along with all the use-cases of Read Committed Isolation Level and Repeatable Reads Isolation Level.
Both Phantom Reads and Write Skew can be solved if the Transactions were executed one after the other. This is the fundamental idea behind the Serializable Isolation Level.
Serializable Isolation Level is the most stringent isolation level and it is very expensive in terms of performance. Most databases don’t support this as a default option due to performance impact.
The basic idea behind Serializable Isolation Level is transactions run in a totally isolated manner as if all the transactions in the database are executed in a sequential manner one after the other.
This doesn’t mean all transactions run sequentially internally. It just means that the resultant output of executing transactions is the same as if the transactions are run sequentially.
Implementation
There are largely two ways of implementing Serializable Isolation Level
- Two-Phase Locking (Pessimistic Locking Technique)
- SSI (Optimistic Locking Technique)
2PL
Two-Phase Locking (2PL) is a Pessimistic Locking Technique that revolves around the idea of Locks to achieve Serializability making sure that Transactions block other Transactions from accessing the same data during their lifecycle.
2PL employs two types of Locks: Shared Locks (Reads Locks) and Exclusive Locks (Write Locks).
The general idea behind these locks is that multiple Transactions can acquire Shared Locks and read the same rows concurrently. If one of the Transactions has to perform write, it has to take an Exclusive Lock on the rows and has to wait for all the Shared Locks to be released.
Similarly, if a Transaction has taken an Exclusive Lock on certain rows, all Reads must wait for the Exclusive Lock to be released before acquiring Shared Locks.
In other words, Reads block Writes and Writes block Reads.
In 2PL, locks are applied in two phases
- Expanding phase: Locks are acquired and no locks are released.
- Shrinking phase: Locks are released and no locks are acquired.
The major downside of 2PL is its performance due to locking acquisition and release and contention due to waiting for locks to be released.
SSI
Serializable Snapshot Isolation (SSI) is an optimistic locking to achieve Serializability which extends Snapshot Isolation.
SSI is a relatively new technique developed around 2008 and is part of the Postgresql 9.1 version.
SSI works on the idea of Snapshot Isolation — all reads within a transaction are from a consistent snapshot at the start of Transaction. On top of Snapshot Isolation, SSI adds a layer of Serializability for detecting conflicts while committing and aborting the Transaction.
The biggest upside of SSI compared to 2PL is performance as it avoids locking and contention-related problems.
Lost Update Problem
Lost Update Problem is a classic problem statement where-in the client reads some value from the database, modifies it, and updates it back to the database via different database Transactions. This is commonly referred to as the Read-Modify-Write cycle.
In the presence of concurrent writes of Read-Modify-Write cycles, two clients can overwrite each other’s value.
Let’s try to understand this with an example.
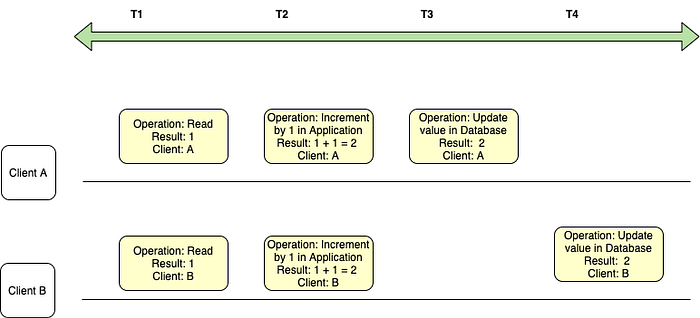
In the above diagram, we have a timeline from T1 to T4. Two clients are trying to update the value in the database by 1 (increment by 1).
- Time T1: Both Clients A and B read the value from the database which is 1
- Time T2: Both Clients A and B carry on some business logic and finally increment the value by 1 in the application
- Time T3: Client A updates the final value in the database to 2
- Time T4: Client B updates the final value in the database to 2
We might be expecting the final value to be 3, but since these two clients are updating the values without knowing about each other, they overwrite the work done by the other client.
Since this is a common problem in the database world, there are various approaches to solve this problem.
- Atomic Update: Most of the databases support atomic updates (or increments) out of the box which allows the client to move the operation to the database which performs these updates and increments sequentially and atomically.
// MySQL
UPDATE users SET counters = counters + 1 WHERE user_id = :user_id// Redis
// INCR key
2. CAS: CAS stands for Compare and Swap. CAS is a kind of operation which is supported in many databases which allow the value to be replaced/updated provided the previous value matches.
// MySQL
UPDATE users SET counters = 5 WHERE user_id = :user_id AND counter = 4A natural extension of CAS is version-based updates where we read the value from the database along with the version and while updating, we replace only if the version was the same as what was read.
3. Explicit Locking: There are certain scenarios where CAS and Atomic Updates cannot be applied when we have a group of operations. Such cases can be solved using Explicit Locking using a particular key which prevents concurrent clients from entering the critical section making it sequential.
Conclusion
This completes the high-level discussion on Database Isolation Level and the fundamental use cases it caters to and how it is internally implemented.
